
Nếu bạn đang xây dựng hệ thống AI có khả năng trả lời câu hỏi dựa trên dữ liệu nội bộ, hẳn bạn đã nghe qua — hoặc đang dùng — RAG. Nhưng gần đây một thuật ngữ mới xuất hiện ngày càng nhiều trong các tài liệu kỹ thuật: Agentic RAG. Và không ít người đang tự hỏi: đây là buzz word mới hay thực sự có gì khác biệt đáng để học?
Câu trả lời ngắn: khác biệt thực sự — và khá lớn. Bài này sẽ giải thích từng khái niệm liên quan, so sánh rõ ràng, và hướng dẫn cách bắt đầu implement Agentic RAG trong thực tế.
Nhắc lại: RAG truyền thống là gì?


Trước khi nói về Agentic RAG, cần hiểu rõ RAG truyền thống làm gì — và tại sao nó chưa đủ.
RAG (Retrieval-Augmented Generation) là kỹ thuật kết hợp hai bước: retrieve (tìm kiếm thông tin liên quan từ knowledge base) và generate (dùng thông tin đó để trả lời). Thay vì chỉ dựa vào kiến thức có sẵn trong training data — vốn có ngưỡng cutoff và không biết gì về dữ liệu nội bộ của công ty bạn — RAG cho phép LLM truy cập vào nguồn dữ liệu bên ngoài trước khi trả lời.
Luồng của RAG truyền thống rất thẳng, theo một đường:
User hỏi → Embed câu hỏi → Tìm top-K chunk trong vector DB → Nhét vào prompt → LLM trả lờiĐơn giản, dễ implement, và hoạt động tốt cho các câu hỏi đơn giản. Nhưng vấn đề bắt đầu xuất hiện khi câu hỏi phức tạp hơn:
- Multi-hop questions: “So sánh doanh thu Q1 2024 và Q1 2025, sau đó giải thích nguyên nhân chênh lệch” — RAG truyền thống lấy được document nhưng không tổng hợp được reasoning
- Dữ liệu nằm ở nhiều nguồn: câu trả lời nằm một phần trong SQL database, một phần trong PDF báo cáo — RAG truyền thống chỉ query được một nguồn
- Không tự kiểm tra chất lượng: nếu chunk tìm được không thực sự liên quan, RAG vẫn dùng nó để generate — không có bước verify
- Cứng nhắc: không thể tự điều chỉnh query nếu kết quả đầu tiên không tốt
Có một analogy khá hay: RAG truyền thống giống như đến thư viện với một tờ giấy ghi sẵn tên sách cần tìm — nếu sách đó có, bạn lấy được; nếu không, bạn về tay không. Không có khả năng tìm cách khác hay hỏi thủ thư để được gợi ý thêm.
Agentic RAG là gì?

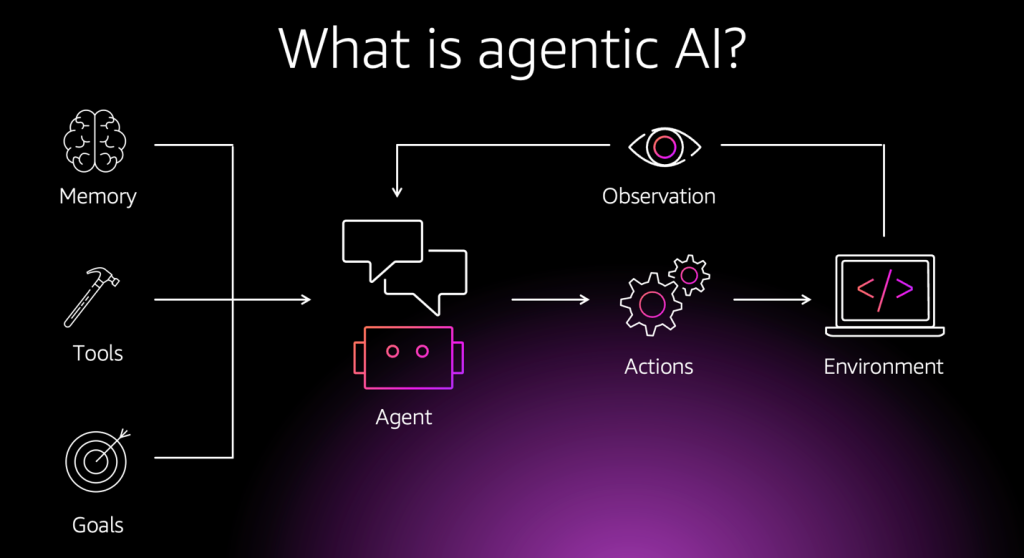
Agentic RAG là kiến trúc bổ sung một lớp agent vào trên RAG pipeline. Thay vì chạy theo đường thẳng cố định, agent có khả năng lập kế hoạch, ra quyết định, lặp lại, và tự điều chỉnh trong suốt quá trình tìm kiếm và trả lời.
Nếu RAG truyền thống là một ống nước — nước chỉ chảy một chiều từ A đến B — thì Agentic RAG là một nhạc trưởng: nó điều phối nhiều nhạc cụ (tools, data sources, verifier) và có thể yêu cầu một phần chơi lại nếu chưa đúng.
Các thuật ngữ cần biết
Khi đi sâu vào Agentic RAG, bạn sẽ gặp một mớ thuật ngữ. Mình tổng hợp lại để bạn có bức tranh tổng thể:
- Agent: Thực thể AI có khả năng nhận thức (perceive), lập kế hoạch (plan), và hành động (act) để đạt mục tiêu. Trong Agentic RAG, agent đóng vai trò “não” điều phối toàn bộ pipeline.
- Tool calling: Khả năng của LLM gọi đến các công cụ bên ngoài — vector search, SQL query, web search, calculator — và sử dụng kết quả trả về để tiếp tục reasoning.
- Router Agent: Agent chuyên phân tích câu hỏi và quyết định nên dùng nguồn dữ liệu nào — vector DB, SQL database, hay web search — thay vì luôn dùng một nguồn cố định.
- Self-RAG: Pattern mà agent tự đánh giá chất lượng của câu trả lời mình vừa generate: liệu nó có thực sự trả lời được câu hỏi không? Nếu chưa, tự reformulate query và search lại.
- CRAG (Corrective RAG): Pattern mà agent đánh giá chất lượng của từng document retrieve được — nếu document không đủ liên quan, tự động mở rộng search ra web hoặc nguồn khác.
- Multi-agent RAG: Nhiều agent chạy song song, mỗi agent search ở một nguồn dữ liệu khác nhau, sau đó một aggregator agent tổng hợp kết quả lại.
- Reranker: Model phụ đánh giá lại độ liên quan của các chunk đã retrieve, sắp xếp theo thứ tự ưu tiên trước khi đưa vào LLM.
- Vector Database: Nơi lưu trữ embedding của các document, cho phép semantic search — tìm kiếm theo nghĩa chứ không chỉ theo từ khóa. Phổ biến: Pinecone, Qdrant, Weaviate, pgvector.
- Chunk: Đơn vị nhỏ nhất của document sau khi được cắt ra để index. Kích thước chunk ảnh hưởng trực tiếp đến chất lượng retrieval.
- Embedding: Biểu diễn văn bản dưới dạng vector số — cơ sở để tính “độ gần” về mặt ngữ nghĩa giữa câu hỏi và document.
Traditional RAG vs Agentic RAG: So sánh trực tiếp
| Traditional RAG | Agentic RAG | |
|---|---|---|
| Luồng xử lý | Tuyến tính, một chiều | Vòng lặp, có thể quay lại |
| Nguồn dữ liệu | Một nguồn cố định | Nhiều nguồn, tự chọn phù hợp |
| Kiểm tra chất lượng | Không có | Tự đánh giá và retry nếu kém |
| Multi-step reasoning | Hạn chế | Tự phân nhỏ và giải quyết từng bước |
| Chi phí | Thấp | Cao hơn (nhiều LLM call hơn) |
| Độ phức tạp | Đơn giản | Phức tạp hơn, cần orchestration |
| Phù hợp với | Q&A đơn giản, FAQ bot | Phân tích phức tạp, enterprise search |

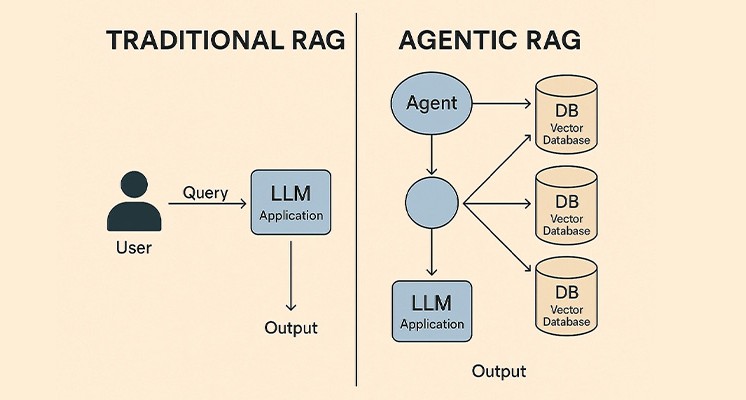
Các pattern phổ biến trong Agentic RAG
Không có một kiến trúc Agentic RAG “chuẩn” duy nhất — tùy bài toán mà bạn chọn pattern phù hợp. Đây là bốn pattern được dùng nhiều nhất:
1. Router Pattern
Agent đầu tiên phân tích câu hỏi và quyết định nên đi vào nguồn dữ liệu nào. Ví dụ: câu hỏi về chính sách công ty → đi vào vector DB nội bộ; câu hỏi cần số liệu real-time → đi vào SQL; câu hỏi cần thông tin mới nhất → đi vào web search.
Câu hỏi → Router Agent → [Vector DB | SQL Database | Web Search]
↓
Tổng hợp kết quả → LLM → Trả lờiDùng khi: Hệ thống có nhiều loại dữ liệu khác nhau, câu hỏi của user đa dạng không thể dự đoán trước sẽ cần nguồn nào.
2. Self-RAG Pattern
Sau khi generate câu trả lời, agent tự hỏi: “Câu trả lời này có thực sự giải quyết được câu hỏi gốc không?” Nếu không, agent reformulate query và thực hiện lại quá trình retrieval.
Câu hỏi → Retrieve → Generate → [Đánh giá chất lượng]
↓ ↓
Đạt yêu cầu Chưa đạt
↓ ↓
Trả lời Rewrite query → Retrieve lạiDùng khi: Cần độ chính xác cao, không chấp nhận hallucination — ví dụ hệ thống Q&A cho legal, finance, hay y tế.
3. CRAG (Corrective RAG) Pattern
Thay vì đánh giá câu trả lời cuối cùng, CRAG đánh giá từng document ngay sau khi retrieve — trước khi đưa vào LLM. Document nào không đủ liên quan bị loại bỏ; nếu không còn document nào tốt, agent mở rộng tìm kiếm ra web hoặc nguồn khác.
Dùng khi: Knowledge base nội bộ có nhiều “noise” — document lỗi thời hoặc không đủ coverage, cần kết hợp thêm nguồn bên ngoài.
4. Multi-Agent RAG Pattern
Nhiều agent chạy song song, mỗi agent chuyên trách một nguồn dữ liệu riêng. Một orchestrator agent tổng hợp kết quả từ tất cả agent con lại để đưa ra câu trả lời cuối cùng.
┌─ Agent A: search Vector DB ─┐
Câu hỏi → Orchestrator ─ Agent B: query SQL DB ──── Aggregator → Trả lời
└─ Agent C: web search ────────┘Dùng khi: Câu hỏi cần tổng hợp từ nhiều nguồn hoàn toàn khác nhau, cần tốc độ (vì chạy song song), ví dụ hệ thống báo cáo tổng hợp cho C-level.
Framework nào để implement?
Đây là câu hỏi mình nhận được nhiều nhất khi nói về Agentic RAG. Hệ sinh thái đang thay đổi nhanh — đây là bức tranh hiện tại:
LangGraph
Sản phẩm của team LangChain, được thiết kế đặc biệt cho agentic workflow. Điểm mạnh là hỗ trợ cycle natively — khác với các DAG truyền thống chỉ chạy một chiều, LangGraph cho phép agent loop lại các bước trước khi đã đủ điều kiện. Phù hợp cho hệ thống phức tạp với nhiều nhánh rẽ và retry logic.
Chọn khi: Cần workflow phức tạp, nhiều agent, human-in-the-loop, hoặc đang dùng LangSmith để observability.
LlamaIndex
Vốn là framework RAG mạnh nhất về phía retrieval — document ingestion, indexing, và query routing đều rất mature. Gần đây ra thêm LlamaIndex Workflows (event-driven, async-first) để build agentic system. Code Python thuần, ít boilerplate hơn LangGraph.
Chọn khi: Data-heavy workload, cần retrieval quality cao, document đa dạng format (PDF, SQL, Notion, Slack…).
LangChain
Framework ban đầu, vẫn là lựa chọn nhanh nhất để prototype. Ecosystem lớn với hàng trăm integrations. Tuy nhiên team LangChain hiện đang đẩy LangGraph như primary choice cho production agentic system.
Chọn khi: Cần prototype nhanh, thử nghiệm nhiều chiến lược retrieval khác nhau trước khi chốt kiến trúc.
Lưu ý thực tế năm 2026: Context window của các model mới (1M+ tokens) đang đặt ra câu hỏi thú vị: với câu hỏi đơn giản, đôi khi nhét thẳng cả document vào context còn nhanh hơn và chính xác hơn cả một RAG pipeline phức tạp. RAG — đặc biệt Agentic RAG — vẫn cần thiết khi dữ liệu quá lớn, cần cập nhật real-time, hoặc khi cost của việc process cả triệu token mỗi query là không chấp nhận được.
Ví dụ thực tế: Xây dựng Agentic RAG đơn giản với LangGraph

Hãy xem qua một ví dụ cụ thể — implement Self-RAG pattern với LangGraph. Đây là skeleton code để bạn có thể hình dung cấu trúc:
from langgraph.graph import StateGraph, END
from typing import TypedDict, List
# Định nghĩa state của graph
class RAGState(TypedDict):
question: str
documents: List[str]
generation: str
retry_count: int
# Node 1: Retrieve documents
def retrieve(state: RAGState):
docs = vectorstore.similarity_search(state["question"], k=4)
return {"documents": docs}
# Node 2: Grade documents — loại bỏ document không liên quan
def grade_documents(state: RAGState):
relevant_docs = []
for doc in state["documents"]:
score = grader_llm.invoke({
"question": state["question"],
"document": doc
})
if score == "relevant":
relevant_docs.append(doc)
return {"documents": relevant_docs}
# Node 3: Generate answer
def generate(state: RAGState):
answer = llm.invoke({
"context": state["documents"],
"question": state["question"]
})
return {"generation": answer}
# Node 4: Kiểm tra answer có đủ tốt không
def grade_generation(state: RAGState):
score = answer_grader.invoke({
"question": state["question"],
"generation": state["generation"]
})
return score # "useful" hoặc "not useful"
# Node 5: Rewrite query nếu cần
def rewrite_question(state: RAGState):
better_question = question_rewriter.invoke(state["question"])
return {
"question": better_question,
"retry_count": state["retry_count"] + 1
}
# Điều kiện: tiếp tục hay kết thúc
def decide_next_step(state: RAGState):
if state["retry_count"] >= 2:
return END # Tránh vòng lặp vô tận
if len(state["documents"]) == 0:
return "rewrite_question"
return "generate"
# Build graph
workflow = StateGraph(RAGState)
workflow.add_node("retrieve", retrieve)
workflow.add_node("grade_documents", grade_documents)
workflow.add_node("generate", generate)
workflow.add_node("rewrite_question", rewrite_question)
workflow.set_entry_point("retrieve")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges("grade_documents", decide_next_step)
workflow.add_edge("generate", END)
workflow.add_edge("rewrite_question", "retrieve")
app = workflow.compile()Nhìn vào code, bạn có thể thấy điểm khác biệt cốt lõi so với RAG truyền thống: add_conditional_edges là nơi agent “ra quyết định” — dựa vào chất lượng document retrieve được, nó có thể đi thẳng sang generate hoặc quay lại rewrite câu hỏi và retrieve lại. Đây chính là vòng lặp mà RAG truyền thống không có.
Khi nào dùng Agentic RAG — và khi nào không cần?
Agentic RAG mạnh hơn, nhưng không có nghĩa là luôn phù hợp hơn. Thực tế, có những trường hợp bạn nên cân nhắc kỹ:
✅ Nên dùng Agentic RAG khi:
- Câu hỏi cần multi-step reasoning: so sánh, tổng hợp từ nhiều nguồn, phân tích nhân quả
- Dữ liệu nằm ở nhiều nguồn khác nhau: SQL DB, vector DB, API, web
- Cần độ chính xác cao và không chấp nhận hallucination
- Query của user đa dạng và khó đoán trước
❌ Không nhất thiết cần Agentic RAG khi:
- Câu hỏi đơn giản, chỉ cần lookup một nguồn dữ liệu cố định
- Latency là ưu tiên hàng đầu — Agentic RAG tốn nhiều LLM call hơn, chậm hơn
- Budget hạn chế — mỗi vòng lặp retry đều tốn thêm token
- Team chưa có kinh nghiệm với agent orchestration — bắt đầu với RAG truyền thống trước, refine sau
Tổng kết
Agentic RAG không phải buzz word — đây là bước tiến hóa tự nhiên khi bài toán enterprise trở nên phức tạp hơn khả năng của RAG pipeline tuyến tính. Nhưng cũng không nên overengineer từ đầu: bắt đầu với RAG truyền thống, xác định rõ điểm nào đang fail, rồi mới thêm dần lớp agentic vào những chỗ thực sự cần.
Những điểm cốt lõi cần nhớ:
- RAG truyền thống = pipeline tuyến tính, một nguồn, không tự kiểm tra — tốt cho câu hỏi đơn giản
- Agentic RAG = agent điều phối, nhiều nguồn, vòng lặp tự cải thiện — cho bài toán phức tạp
- 4 pattern chính: Router, Self-RAG, CRAG, Multi-Agent — chọn theo bài toán cụ thể
- Framework: LangGraph cho workflow phức tạp, LlamaIndex cho data-heavy, LangChain cho prototype nhanh
- Trade-off thực tế: Agentic RAG chính xác hơn nhưng chậm hơn và tốn hơn — cân đo theo nhu cầu
Nếu bạn đang build hệ thống RAG cho production, điểm bắt đầu thực tế nhất là: implement Router pattern trước — nó đơn giản nhất trong bốn pattern trên nhưng đã giải quyết được phần lớn vấn đề của RAG truyền thống với dữ liệu đa nguồn.
Chúc anh em code vui! 🚀
Tags: #rag #agenticrag #llm #ai #langchain #langgraph #llamaindex #vectordatabase #machinelearning