Khoảng 1-2 năm trước, nếu ai đó nói với mình rằng sẽ có một vai trò gọi là “Agentic AI Engineer” — người chuyên xây dựng các hệ thống AI có thể tự lập kế hoạch, tự gọi công cụ, và tự hoàn thành task mà không cần con người can thiệp từng bước — mình sẽ nghĩ đó là chức danh trong một bộ phim khoa học viễn tưởng.
Giờ thì đây là một trong những vị trí được săn đón nhiều nhất trong ngành tech năm 2026. Và quan trọng hơn: lộ trình để đến đó rõ ràng hơn bạn nghĩ — không phải học lung tung rồi xem sao, mà có thứ tự cụ thể từng bước.
Bài viết này tổng hợp lại lộ trình đó — từ nền tảng lập trình cho đến khi bạn có thể deploy một hệ thống agentic thực sự lên production.
Agentic AI Engineer là ai?
Trước khi đi vào lộ trình, mình muốn làm rõ vai trò này thực sự làm gì — vì “Agentic AI Engineer” là cụm từ mới và dễ bị hiểu nhầm.
Đây không phải là nhà nghiên cứu AI training model mới. Cũng không phải chỉ là developer biết gọi OpenAI API. Agentic AI Engineer là người thiết kế và xây dựng hệ thống trong đó AI model đóng vai trò agent — có khả năng nhận mục tiêu, tự lập kế hoạch, gọi các công cụ bên ngoài (search, database, API), đánh giá kết quả, và lặp lại cho đến khi task hoàn thành.
Nếu AI Engineer truyền thống là người xây dựng cái ống dẫn nước — thì Agentic AI Engineer là người thiết kế cả hệ thống thủy lợi: nhiều ống, nhiều van, có sensor tự điều chỉnh, và có thể tự xử lý khi một đoạn nào đó bị tắc.
Lộ trình để đến vai trò này đi theo triết lý “foundation-first” — nền tảng trước, framework sau. Cố học LangChain trước khi hiểu rõ Python async hay context window là con đường ngắn nhất để bị mắc kẹt ở giữa lộ trình.
Thứ tự học tóm gọn
Trước khi đi chi tiết, đây là bức tranh tổng thể để bạn không bị lạc:
Python → LLM → Framework → Workflow → Memory → Tools → RAG → Multi-Agents → Production9 bước. Mỗi bước là nền tảng cho bước tiếp theo. Bỏ qua hoặc học qua loa một bước sẽ khiến bạn gặp khó ở các bước sau — không phải vì nó khó về mặt kỹ thuật, mà vì bạn sẽ không hiểu tại sao mọi thứ được thiết kế theo cách đó.
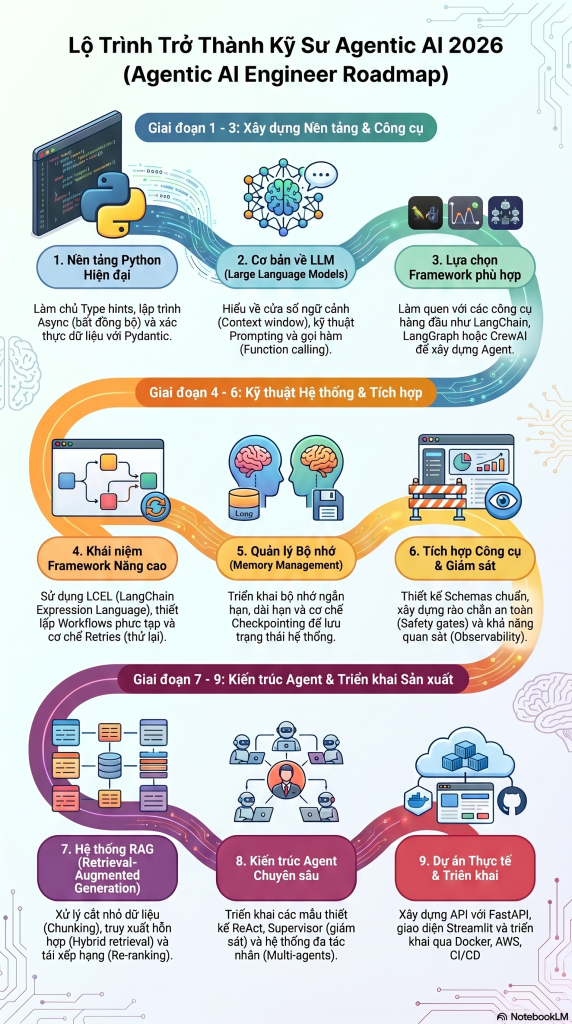
Giai đoạn 1: Nền tảng — Python và LLM
Python cho Agentic AI — Không phải Python bình thường
Nếu bạn đã biết Python cơ bản, đừng nghĩ là mình đã xong bước này. Python cho agentic system cần một vài thứ cụ thể mà khóa học Python thông thường không dạy:
- Type hints và Pydantic: Trong hệ thống agentic, data validation là sống còn. Khi agent gọi một công cụ và nhận dữ liệu về, nếu schema sai mà không có validation, toàn bộ pipeline có thể fail theo cách rất khó debug. Pydantic là thứ bạn sẽ dùng mọi lúc — học nó kỹ ngay từ đầu.
- Async programming: Hầu hết các tác vụ trong agentic system là IO-heavy — gọi API, query database, gọi LLM, tất cả đều phải chờ. Nếu viết theo kiểu synchronous, agent của bạn sẽ ngồi idle 80% thời gian.
asyncio,async/await, và cách tổ chức concurrent tasks là thứ bắt buộc phải biết. - Cấu trúc project phân lớp: Tách biệt rõ ràng giữa prompt logic và business logic. Nghe có vẻ không quan trọng ở project nhỏ — nhưng khi hệ thống có 10+ agent, 20+ tool, và cần maintain lâu dài, cấu trúc kém sẽ tạo ra technical debt không thể gỡ.
Nguyên lý LLM — Hiểu từ bên trong
Bạn không cần hiểu toán học đằng sau transformer để làm agentic AI — nhưng có một vài khái niệm bạn phải thực sự hiểu chứ không chỉ biết tên:
- Token và context window: Context window không phải vô hạn. Trong một agentic pipeline dài — nhiều bước, nhiều tool call, nhiều kết quả — context sẽ bị đầy. Hiểu cách tính token, cách context được sử dụng, và kỹ năng “context budgeting” — phân bổ context có chủ đích cho từng phần của pipeline — là thứ phân biệt hệ thống chạy được trong production với hệ thống chỉ chạy được khi demo.
- Function calling: Đây là cơ chế cốt lõi cho phép LLM tương tác với thế giới bên ngoài. Thay vì model chỉ trả về text, function calling cho phép model nói “tôi cần gọi công cụ X với tham số Y” — sau đó code của bạn thực thi và trả kết quả về. Hiểu sâu cơ chế này là nền tảng của toàn bộ tool integration.
Giai đoạn 2: Framework và Kiến trúc
Chọn framework nào?
Đây là câu hỏi mình thấy nhiều người mắc kẹt nhất — vì cộng đồng hay tranh luận LangChain vs CrewAI vs AutoGen như thể phải chọn một cái để “trung thành” suốt đời. Thực tế không phải vậy.
- LangChain/LangGraph: Mạnh nhất về state graph — bạn định nghĩa các node (bước xử lý) và edge (điều kiện chuyển tiếp), LangGraph quản lý flow. Phù hợp khi workflow có nhiều nhánh rẽ, retry logic phức tạp, hay cần human-in-the-loop ở các điểm cụ thể.
- CrewAI: Tối ưu cho multi-agent collaboration theo vai trò — bạn định nghĩa “crew” gồm các agent với role cụ thể (Researcher, Writer, Reviewer…) và CrewAI quản lý việc phối hợp. Phù hợp khi bài toán tự nhiên được chia thành các vai trò chuyên biệt.
- AutoGen: Framework của Microsoft, mạnh về conversational agents và human-AI collaboration flow.
Lời khuyên thực tế: học LangGraph trước — nó đòi hỏi bạn hiểu rõ nhất về cách agent hoạt động ở mức thấp. Khi đã nắm vững, chuyển sang CrewAI hay AutoGen sẽ dễ hơn nhiều vì bạn biết “bên dưới chúng đang làm gì”.
Khái niệm quan trọng: Retry và Fallback
Hệ thống agentic là hệ thống bất định — cùng một input có thể cho ra output khác nhau mỗi lần chạy. LLM có thể timeout, tool call có thể fail, kết quả có thể không đủ chất lượng. Thiết kế retry logic và fallback strategy không phải là “nice to have” — đây là điều bắt buộc nếu bạn muốn hệ thống chạy được trong production.
LCEL (LangChain Expression Language) cung cấp pattern .with_retry() và .with_fallbacks() — giúp bạn xây dựng các pipeline có khả năng tự phục hồi mà không phải viết boilerplate retry code thủ công.
Giai đoạn 3: Các thành phần cốt lõi của hệ thống Agentic
Memory Management — Bộ nhớ ngắn hạn và dài hạn
Agent cần nhớ — nhưng “nhớ” trong hệ thống AI không tự nhiên như với con người. Bạn cần thiết kế rõ ràng hai tầng bộ nhớ:
- Bộ nhớ ngắn hạn: Nằm trong context window của conversation hiện tại — những gì đã xảy ra trong phiên làm việc này. Giới hạn bởi context window, cần quản lý cẩn thận để không bị đầy.
- Bộ nhớ dài hạn: Lưu trong vector store hay database — thông tin cần được giữ lại qua nhiều phiên, nhiều conversation. Thiết kế phần này đòi hỏi quyết định về embedding model, indexing strategy, và retrieval mechanism.
Một khái niệm quan trọng không kém: checkpointing — lưu trạng thái của workflow tại các điểm kiểm tra cụ thể. Khi agent đang chạy một task dài 20 bước và fail ở bước 18, bạn không muốn phải chạy lại từ đầu. Checkpoint cho phép resume từ điểm gần nhất.
Tool Integration — Thiết kế công cụ “thân thiện với agent”
Không phải công cụ nào cũng phù hợp để agent gọi. Khi thiết kế tool cho agentic system, có 3 nguyên tắc quan trọng:
- Schema đầu vào rõ ràng: Agent quyết định gọi tool nào dựa trên description và input schema. Schema càng rõ ràng, agent càng gọi đúng — và kết quả trả về càng có thể predict được. Pydantic lại xuất hiện ở đây.
- Sandbox an toàn: Đặc biệt với các tool có side effect (gửi email, ghi file, gọi API có phí…) — cần có cơ chế sandbox để test mà không gây hậu quả thật, và cơ chế confirm trước khi thực thi hành động không thể undo.
- Least privilege: Mỗi tool chỉ được cấp quyền tối thiểu cần thiết để làm việc. Agent không cần quyền delete thì không cho quyền delete — dù bạn chắc chắn agent sẽ không xóa gì. Đây là nguyên tắc bảo mật cơ bản nhưng hay bị bỏ qua khi mải tập trung vào feature.
RAG — Nền tảng để agent “biết” về domain của bạn
RAG (Retrieval-Augmented Generation) là cơ chế cho phép agent truy cập knowledge base ngoài training data — tài liệu nội bộ, database, hay bất kỳ nguồn thông tin nào bạn cung cấp. Trong agentic system, RAG không chỉ là “tìm kiếm rồi nhét vào prompt” — nó là một component phức tạp cần được thiết kế kỹ:
- Chunking strategy: Cắt document như thế nào ảnh hưởng trực tiếp đến chất lượng retrieval. Chunk quá lớn sẽ làm loãng thông tin; chunk quá nhỏ sẽ mất context. Không có công thức chung — cần experiment với từng loại document.
- Hybrid retrieval: Kết hợp semantic search (vector similarity) với keyword search (BM25) thường cho kết quả tốt hơn dùng một mình. Semantic search giỏi tìm theo nghĩa; keyword search giỏi tìm theo thuật ngữ chính xác — hai cái bổ sung cho nhau.
- Re-ranking: Sau khi retrieve top-K results, dùng một model phụ để sắp xếp lại theo độ liên quan thực sự trước khi đưa vào LLM. Bước này giảm đáng kể tỷ lệ hallucination.
Giai đoạn 4: Thiết kế Agent và Production
Mô hình ReAct và Supervisor Pattern
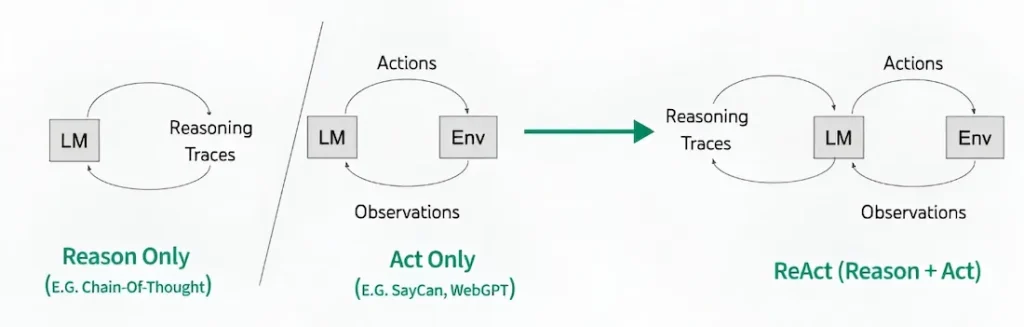
ReAct (Reason + Act) là mô hình agent phổ biến nhất hiện tại. Thay vì agent nhận input và trả output ngay, ReAct tạo ra một vòng lặp: Suy nghĩ → Quyết định hành động → Thực thi → Quan sát kết quả → Suy nghĩ tiếp — cho đến khi task hoàn thành hoặc đến giới hạn số vòng lặp.
Khi hệ thống có nhiều agent chuyên biệt, bạn cần Supervisor Pattern: một agent điều phối (supervisor) nhận task từ user, phân tích, và giao cho đúng agent chuyên biệt xử lý — sau đó tổng hợp kết quả lại. Agent viết code, agent research, agent review — supervisor biết giao việc cho ai và khi nào.
Tech stack cho production
Khi đã có agent hoạt động được, bước tiếp theo là đóng gói và deploy. Stack phổ biến nhất hiện tại:
- FastAPI cho backend: xây dựng API endpoint để expose agent — async native, type hints, tự generate Swagger docs
- Streamlit cho UI nhanh: không cần frontend engineer để có một giao diện tương tác được — phù hợp cho internal tools hay prototype
- Docker để đóng gói: đảm bảo “chạy được trên máy mình” cũng chạy được trên server production
- AWS/GCP/Azure để deploy: tùy vào organization, nhưng biết cách deploy lên ít nhất một cloud provider là bắt buộc
Observability — Thứ mà beginner hay bỏ qua nhất
Hệ thống agentic có tính chất bất định — không phải lúc nào cũng cho ra cùng một kết quả với cùng một input. Debugging một hệ thống như vậy mà không có observability giống như lái xe trong sương mù: bạn biết mình đang đi nhưng không biết mình đang ở đâu hay đã đi lệch hướng từ khi nào.
Ba loại metric cần theo dõi từ ngày đầu:
- Success rate: Bao nhiêu % task được hoàn thành đúng? Tỷ lệ này phải được đo theo từng loại task, không phải chung chung.
- Latency: Mỗi bước trong pipeline mất bao lâu? Bước nào là bottleneck? Đặc biệt quan trọng với agentic system vì mỗi LLM call tốn thời gian và có thể tích lũy thành một pipeline rất chậm.
- Cost: Mỗi execution tốn bao nhiêu token, tương đương bao nhiêu tiền? Hệ thống agentic có thể tốn kém bất ngờ nếu không có cost tracking — đặc biệt khi agent bị vòng lặp hay gọi tool quá nhiều lần.
Ngoài metrics, cần có trace logging: ghi lại toàn bộ “thought process” của agent — nó đã nghĩ gì, gọi tool nào, nhận kết quả gì, và quyết định bước tiếp theo như thế nào. Không có trace, bạn không thể debug khi agent làm sai.
Tóm tắt lộ trình và thứ tự ưu tiên
Nếu bạn đang ở điểm xuất phát và cần biết học gì trước, đây là cách mình sẽ sắp xếp:
- Python nâng cao — type hints, Pydantic, async. Đừng bỏ qua vì nghĩ mình đã biết Python.
- LLM fundamentals — token, context window, function calling. Dùng thẳng API không qua framework để hiểu bên dưới hoạt động như thế nào.
- LangGraph — build một workflow đơn giản có branch và retry. Hiểu state graph trước khi dùng abstraction cao hơn.
- Memory và checkpointing — thêm bộ nhớ dài hạn vào workflow, implement checkpoint đơn giản.
- Tool design — thiết kế 3-5 tool với Pydantic schema, test với agent thực tế.
- RAG pipeline — build từ chunking → embedding → retrieval → re-ranking, đo chất lượng retrieval.
- Multi-agent system — implement supervisor pattern với 2-3 agent chuyên biệt.
- Production stack — wrap agent trong FastAPI, đóng gói Docker, deploy lên cloud.
- Observability — thêm metrics, logging, trace từ ngày đầu — không phải sau khi có vấn đề.
Mỗi bước nên có một project nhỏ thực tế — không phải tutorial làm theo, mà là bạn tự xác định bài toán và tự giải. Đó là thứ sẽ xuất hiện trong portfolio của bạn, không phải chứng chỉ khóa học.
Tổng kết
Agentic AI Engineer không phải là vai trò xa vời — nó là bước tiến hóa tự nhiên của Software Engineer trong một thế giới mà AI đang trở thành infrastructure. Lộ trình để đến đó dài nhưng rõ ràng, và điểm quan trọng nhất là: thứ tự học quan trọng hơn tốc độ học.
Nhảy thẳng vào framework mà chưa hiểu LLM fundamentals sẽ tạo ra “framework user” — người biết dùng công cụ nhưng không biết tại sao mọi thứ được thiết kế như vậy, và sẽ bị mắc kẹt ngay khi gặp edge case ngoài tutorial.
Tóm lại những gì cần nhớ:
- Foundation-first: Python → LLM → Framework, không nhảy cóc
- Pydantic + async là hai kỹ năng Python quan trọng nhất cho agentic AI
- Function calling là cơ chế cốt lõi của mọi tool integration — hiểu sâu ngay từ đầu
- Memory và checkpointing phân biệt agent “chạy demo” và agent “chạy production”
- Observability không phải option — thiếu metrics và trace, bạn không thể debug hệ thống bất định
- Project thực tế quan trọng hơn chứng chỉ — build, deploy, đo lường, lặp lại
Nếu bạn đã biết Python và đang tự hỏi bắt đầu từ đâu — hãy bắt đầu bằng cách gọi thẳng API của Claude hay OpenAI mà không dùng framework nào, implement function calling thủ công, và build một tool đơn giản. Khi bạn hiểu cơ chế đó hoạt động như thế nào ở mức thấp nhất, mọi framework sau này sẽ chỉ là “syntax khác nhau của cùng một concept”.
Chúc anh em code vui! 🚀
Tags: #agenticai #aiengineering #llm #langchain #langgraph #python #rag #multiagent #roadmap #2026
Khoảng 1-2 năm trước, nếu ai đó nói với mình rằng sẽ có một vai trò gọi là “Agentic AI Engineer” — người chuyên xây dựng các hệ thống AI có thể tự lập kế hoạch, tự gọi công cụ, và tự hoàn thành task mà không cần con người can thiệp từng bước — mình sẽ nghĩ đó là chức danh trong một bộ phim khoa học viễn tưởng.
Giờ thì đây là một trong những vị trí được săn đón nhiều nhất trong ngành tech năm 2026. Và quan trọng hơn: lộ trình để đến đó rõ ràng hơn bạn nghĩ — không phải học lung tung rồi xem sao, mà có thứ tự cụ thể từng bước.