
Có một chi phí ẩn mà nhiều người dùng AI chuyên nghiệp hay bỏ qua — không phải tiền subscription hàng tháng, mà là token. Mỗi lần bạn gửi một đoạn context dài, paste cả file code vào chat, hay để conversation kéo dài hàng chục lượt mà không reset — bạn đang đốt token. Với người dùng cá nhân, điều đó có nghĩa là hết limit sớm hơn. Với team hay enterprise dùng API, điều đó có nghĩa là bill tăng cao hơn kỳ vọng.
Bài này đi thẳng vào vấn đề: token là gì, tại sao quan trọng, và những kỹ thuật cụ thể để tối ưu — với ví dụ thực tế từ Claude. Không phải lý thuyết, mà là những thứ bạn áp dụng được ngay hôm nay.
Token là gì và tại sao phải quan tâm?

Token là đơn vị xử lý của LLM — không hoàn toàn là từ, không hoàn toàn là ký tự, mà là những “mảnh” ngôn ngữ mà model dùng để đọc và tạo ra text. Quy tắc ngón tay cái: 1 token ≈ 4 ký tự tiếng Anh, hay khoảng 100 token ≈ 75 từ. Tiếng Việt và các ngôn ngữ không phải Latin thường tốn nhiều token hơn tiếng Anh cho cùng một lượng thông tin.
Token quan trọng vì hai lý do:
- Context window: Mỗi conversation có giới hạn tổng số token (input + output). Claude Sonnet 4.5 có context window 200K token — nghe có vẻ nhiều, nhưng một codebase vừa vừa paste vào là đầy ngay. Khi đầy, model bắt đầu “quên” những gì ở đầu conversation.
- Chi phí API: Với developer dùng Claude API, input token và output token đều tính tiền. Với người dùng Pro/Max trên claude.ai, limit daily/weekly phụ thuộc vào số token consumed — không phải số message. Một prompt 10.000 token tốn gấp 10 lần prompt 1.000 token, dù chỉ là một lần nhắn.
Điểm mấu chốt: token không phải lần nhắn tin. Bạn có thể gửi 50 message ngắn mà tốn ít token hơn 5 message dài lê thê. Tối ưu token không phải là nhắn ít đi — mà là nhắn thông minh hơn.
Nguyên tắc nền tảng: Precision over verbosity
Trước khi đi vào kỹ thuật cụ thể, có một nguyên tắc cần hiểu rõ: AI không thông minh hơn vì bạn nói nhiều hơn. Ngược lại, prompt càng dài và mơ hồ, model càng tốn token để “đoán” ý bạn — và kết quả thường kém hơn prompt ngắn nhưng rõ ràng.
Nói cách khác: tối ưu token và viết prompt tốt hơn là cùng một việc. Khi bạn loại bỏ thông tin thừa khỏi prompt, bạn vừa tiết kiệm token vừa nhận được câu trả lời tốt hơn — win-win.
Kỹ thuật 1: Cắt bỏ “lời mở đầu xã giao”
Đây là lỗi phổ biến nhất — và dễ fix nhất. Nhiều người có thói quen mở đầu prompt bằng những câu không mang thông tin:
❌ Tốn token không cần thiết:
"Xin chào Claude! Mình đang làm một dự án rất thú vị và cần sự
giúp đỡ của bạn. Mình nghĩ bạn sẽ làm rất tốt điều này.
Liệu bạn có thể giúp mình viết một function Python để..."
✅ Đi thẳng vào vấn đề:
"Viết Python function để parse JWT token, return dict chứa
payload, raise ValueError nếu token invalid hoặc expired."Phiên bản đầu tốn khoảng 50 token chỉ để nói lời chào. Nhân với 30 lần chat mỗi ngày, đó là 1.500 token hoàn toàn vô ích — không giúp Claude trả lời tốt hơn một chút nào.
Kỹ thuật 2: Chỉ paste phần code liên quan, không paste cả file
Đây là nguồn token waste lớn nhất khi làm việc với code. Bạn đang debug một function 20 dòng nhưng paste cả file 500 dòng vào vì… tiện.
❌ Paste cả file (500 dòng = ~3.000 token):
"File này đang bị lỗi, xem giúp mình:
[paste toàn bộ UserService.ts 500 dòng]
Hàm validateEmail đang không hoạt động đúng."
✅ Chỉ paste phần liên quan (~100 token):
"Hàm này đang return true cho email không hợp lệ như 'abc@':
[paste 20 dòng validateEmail function]
Type định nghĩa: type Email = string & { _brand: 'email' }
Lỗi: validateEmail('abc@') trả về true thay vì false."Tiết kiệm 2.900 token cho một câu hỏi. Và kết quả thường tốt hơn — vì Claude tập trung vào đúng phần cần xem, không phải đọc qua 480 dòng không liên quan.
Cách xác định “phần liên quan” cần paste:
- Function/method bị lỗi hoặc cần sửa
- Interface/type definitions mà function đó dùng
- Error message hoặc test case đang fail
- Convention hay pattern đặc biệt của project (nếu Claude chưa biết)
Kỹ thuật 3: Dùng CLAUDE.md hoặc System Prompt thay vì nhắc lại context
Nếu bạn đang phải giải thích lại tech stack, naming convention, hoặc business rule mỗi lần bắt đầu conversation mới — bạn đang lãng phí token theo cách worst-case nhất: lặp đi lặp lại thông tin không thay đổi.
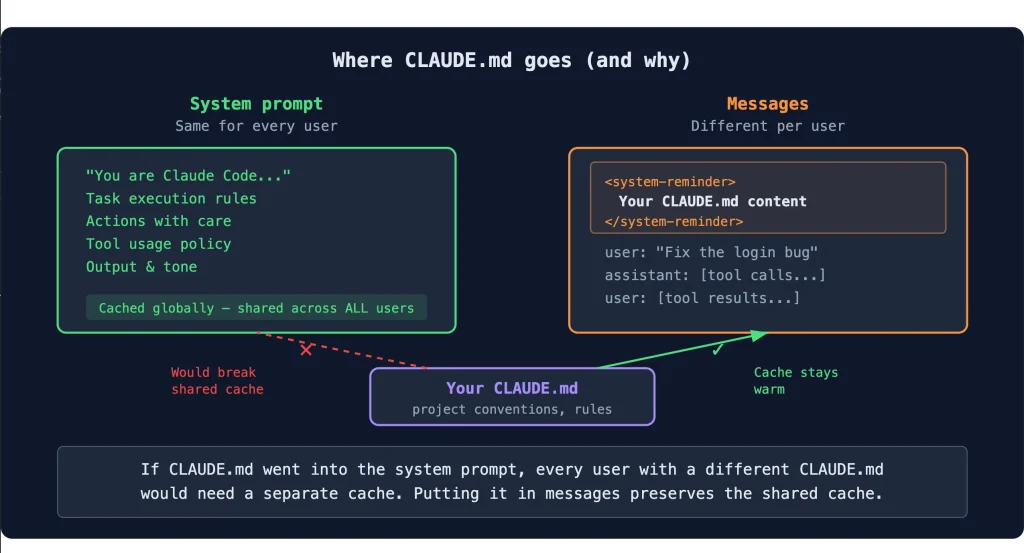
Với Claude Code: File CLAUDE.md ở root project được đọc tự động — viết một lần, mọi conversation trong project đều có context đó mà không cần nhắc lại.
Với Claude.ai: Dùng tính năng Projects với custom instructions — những thông tin như “dự án này dùng TypeScript strict mode, naming convention camelCase, không dùng any” chỉ cần viết một lần trong project settings.
❌ Nhắc lại mỗi lần (mỗi conversation tốn ~200 token):
"Dự án của mình dùng React 18, TypeScript strict mode,
Tailwind CSS, Zustand cho state management. Convention:
component PascalCase, hook bắt đầu bằng 'use', không dùng
default export cho named component. Bây giờ giúp mình..."
✅ Viết một lần trong CLAUDE.md hoặc Project instructions:
[Cài đặt một lần, Claude tự đọc mỗi lần — 0 token overhead
cho mọi conversation sau đó]Với 20 conversation mỗi ngày, tiết kiệm 20 × 200 = 4.000 token — mỗi ngày.
Kỹ thuật 4: Reset conversation đúng lúc
Đây là kỹ thuật counter-intuitive nhất: đôi khi bắt đầu conversation mới tiết kiệm token hơn tiếp tục conversation cũ.
Lý do: mỗi message trong conversation đều được gửi lại kèm theo toàn bộ history. Một conversation có 20 lượt trao đổi, mỗi lượt Claude nhận được tổng cộng toàn bộ 19 lượt trước đó. History càng dài, mỗi message bạn gửi càng tốn nhiều input token — dù nội dung message mới chỉ có 50 từ.
Dấu hiệu nên reset conversation:
- Task đã xong, bạn đang chuyển sang một task hoàn toàn khác
- Conversation đã quá dài và Claude bắt đầu “quên” context đầu
- Bạn muốn thử hướng giải quyết mới mà không bị ảnh hưởng bởi context cũ
Dấu hiệu nên tiếp tục conversation:
- Task liên quan chặt chẽ với nhau, cần Claude nhớ context trước
- Đang iterate trên cùng một đoạn code/văn bản
- Conversation chưa dài và context vẫn còn fresh
Kỹ thuật 5: Yêu cầu output ngắn gọn khi không cần giải thích dài
Output token cũng tốn tiền — và Claude mặc định có xu hướng giải thích khá chi tiết. Nếu bạn chỉ cần code, không cần explanation; hoặc chỉ cần câu trả lời, không cần walkthrough — hãy nói thẳng.
// Thêm vào cuối prompt khi muốn output ngắn:
"Chỉ trả về code, không cần giải thích."
"Trả lời trong 2-3 câu."
"Chỉ liệt kê, không cần elaboration."
"Chỉ phần implementation, bỏ qua boilerplate."Ví dụ cụ thể:
❌ Không nói rõ → Claude giải thích dài (500 token output):
"Viết React hook để debounce một value"
✅ Nói rõ format → Chỉ code (150 token output):
"Viết React hook để debounce một value.
Chỉ code, không cần giải thích. TypeScript."Tiết kiệm 350 token output chỉ bằng một câu thêm vào. Nếu bạn cần giải thích sau, hỏi tiếp — nhưng bắt đầu bằng code ngắn gọn để review trước, giải thích sau nếu cần.
Kỹ thuật 6: Dùng bullet points thay vì câu văn dài trong prompt
Bullet points không chỉ dễ đọc hơn — chúng thường ngắn hơn câu văn đầy đủ vì bỏ được các từ nối không cần thiết. Và Claude đọc bullet points tốt ngang câu văn.
❌ Câu văn dài (~120 token):
"Tôi muốn bạn review đoạn code này và tập trung vào performance,
đặc biệt là các chỗ có thể gây re-render không cần thiết trong React,
cũng như memory leak nếu có, và nếu có thể thì cũng xem qua
naming convention xem có nhất quán không."
✅ Bullet points (~70 token, cùng thông tin):
"Review code này, focus vào:
- Unnecessary re-renders
- Memory leaks
- Naming consistency"Kỹ thuật 7: Tái sử dụng context thay vì repeat
Trong một conversation dài, thay vì paste lại code hoặc giải thích lại vấn đề, hãy refer đến những gì đã nói:
❌ Paste lại code (tốn token):
"Bây giờ với function validateEmail ở trên [paste lại code],
hãy thêm support cho email với subdomain."
✅ Reference ngắn gọn:
"Với validateEmail vừa viết, thêm support cho subdomain email
như user@mail.company.com"Claude đã có function đó trong context — không cần paste lại. Dùng reference ngắn để chỉ đến phần cụ thể.
Kỹ thuật 8: Chọn đúng model cho đúng task
Đây là tối ưu ở cấp độ cao hơn — không phải về cách viết prompt, mà về việc chọn đúng tool cho đúng việc.
Với Claude, có sự đánh đổi rõ ràng giữa các model:
- Claude Haiku: Nhanh nhất, rẻ nhất — phù hợp cho classification, extraction, translation, summarization đơn giản. Với API, Haiku rẻ hơn Sonnet khoảng 20-25x.
- Claude Sonnet: Điểm cân bằng tốt nhất giữa capability và cost — phù hợp cho hầu hết task lập trình, viết lách, phân tích thông thường.
- Claude Opus: Mạnh nhất — chỉ dùng khi thực sự cần: reasoning phức tạp, multi-step planning, task đòi hỏi judgment cao. Tốn token nhất.
Sai lầm phổ biến: dùng Opus cho mọi task vì “mạnh nhất”. Kết quả là tốn 20x chi phí so với Haiku cho một task mà Haiku làm được tốt như nhau.
// Framework chọn model:
Task phân loại / extract data đơn giản → Haiku
Task viết code thông thường / viết lách → Sonnet
Task reasoning phức tạp / multi-step agent → OpusKỹ thuật 9: Cache prompt cho content lặp lại (nâng cao)
Với developer dùng Claude API trực tiếp, Anthropic có tính năng Prompt Caching — cho phép cache phần system prompt hoặc context lớn (ví dụ tài liệu dài), sau đó tái sử dụng cache đó cho nhiều request mà không cần gửi lại toàn bộ token mỗi lần.
Chi phí cache hit chỉ bằng khoảng 10% chi phí input token thông thường — tiết kiệm 90% cost cho phần được cache. Rất hữu ích khi bạn có:
- System prompt dài (coding conventions, business rules…)
- Tài liệu lớn cần reference nhiều lần (API docs, schema database…)
- Codebase context cần nhúng vào nhiều request
// Ví dụ kích hoạt prompt caching trong API call:
{
"model": "claude-sonnet-4-5",
"system": [
{
"type": "text",
"text": "[System prompt dài của bạn]",
"cache_control": { "type": "ephemeral" } // ← Đây là key
}
],
"messages": [...]
}Phần được đánh dấu cache_control sẽ được cache sau lần đầu tiên gửi. Từ request thứ hai trở đi, bạn chỉ trả 10% cost cho phần đó.
Tổng hợp: Checklist tối ưu token hàng ngày
Áp dụng những kỹ thuật trên không cần làm tất cả cùng lúc. Bắt đầu với những cái đơn giản nhất — chúng cũng có tác động lớn nhất:
- ☐ Bỏ lời mở đầu xã giao — đi thẳng vào yêu cầu
- ☐ Chỉ paste code liên quan — không paste cả file
- ☐ Setup CLAUDE.md hoặc Project instructions — không nhắc lại context cố định
- ☐ Yêu cầu output ngắn khi không cần giải thích dài
- ☐ Dùng bullet points trong prompt thay vì câu văn dài
- ☐ Reference thay vì paste lại trong cùng một conversation
- ☐ Reset conversation khi chuyển sang task hoàn toàn mới
- ☐ Chọn đúng model — đừng dùng Opus cho task mà Sonnet làm được
- ☐ Cân nhắc Prompt Caching nếu đang dùng API với context lặp lại
Tổng kết
Tối ưu token không phải là thắt lưng buộc bụng — không phải nhắn ít đi hay dùng AI ít đi. Đó là việc loại bỏ những gì không đóng góp vào chất lượng kết quả. Khi bạn cắt bỏ lời chào vô ích, paste đúng phần code cần thiết, và nói rõ format output mong muốn — bạn vừa tiết kiệm token vừa nhận được câu trả lời tốt hơn.
Trong tất cả các kỹ thuật trên, ba cái có tác động lớn nhất và dễ bắt đầu nhất là:
- Setup CLAUDE.md hoặc Project instructions một lần — tiết kiệm hàng nghìn token mỗi ngày
- Chỉ paste phần code liên quan — không paste cả file
- Yêu cầu output ngắn khi không cần giải thích chi tiết
Bắt đầu từ ba cái đó. Phần còn lại sẽ thành thói quen theo thời gian.
Chúc anh em code vui! 🚀
Tags: #claude #chatgpt #token #promptengineering #aicoding #optimization #llm #productivity
Có một chi phí ẩn mà nhiều người dùng AI chuyên nghiệp hay bỏ qua — không phải tiền subscription hàng tháng, mà là token. Mỗi lần bạn gửi một đoạn context dài, paste cả file code vào chat, hay để conversation kéo dài hàng chục lượt mà không reset — bạn đang đốt token. Với người dùng cá nhân, điều đó có nghĩa là hết limit sớm hơn. Với team hay enterprise dùng API, điều đó có nghĩa là bill tăng cao hơn kỳ vọng.